
{kind=link}

Highlight
- Google Deepmind has revealed another AI that can generate Audio for video using text prompts. This new model is called the V2A (Video-to-Audio)
- This model can synchronize and generate audio for video with video pixel and text prompts
- Currently under more research before release to the public
The Google Research Center Google Deepmind has revealed another AI that can generate Audio for video using text prompts. This new model is called the V2A (Video-to-Audio). This model can give life to videos that didn’t have audio-generating soundtracks and dialogues for videos.
V2A (Video-to-Audio) Model
You have heard above the Text-to-Video Model like Sora of Open AI and VEO of Google that generate video using text prompts but this model generates video only without any sounds. This new technology will allow you to generate and synchronize audio to video using text and video pixels.
V2A can generate sound for video adding sound that matches the video visual like dramatic scores, realistic sound effects, or fitting dialogue that matches the character and mood of the video. This can be a great tool when paired with video-generated models like VEO.
With text prompts, AI gets insight into the mood and type of sounds suitable for the video provided, and you can repeat this until users get the desired sound that matches the video.
How does V2A (Video-to-Audio) work?
In a blog post, Google explains that it begins with the compression of video input. Then, the diffusion model refines the audio and generates sounds from random noise. This is guided by a visual input and text prompt given to generate synchronized, realistic audio that closely aligns with the video and the prompt text given. Lastly, the audio output is decoded, turned into an audio waveform, and combined with the video data.
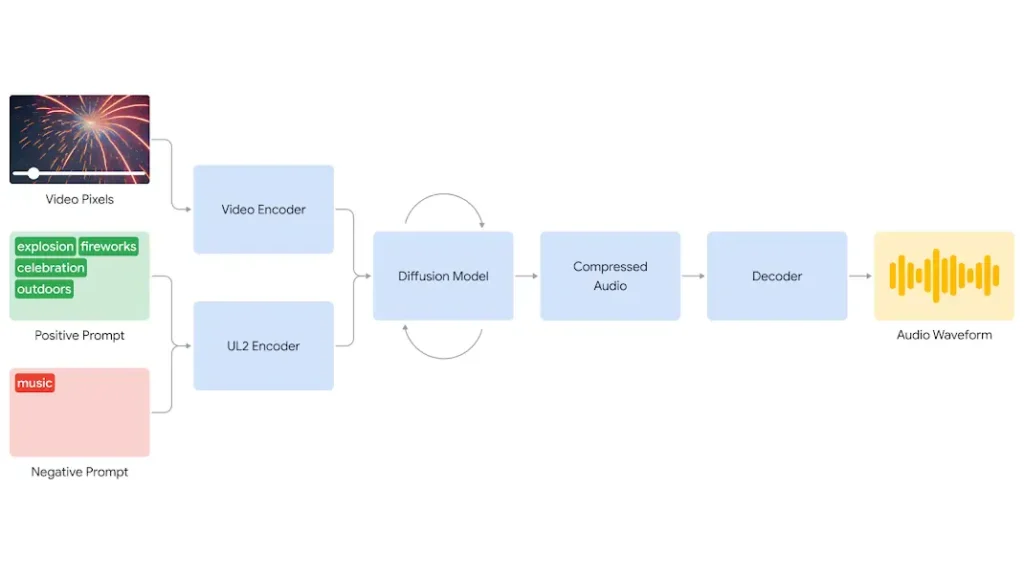
This model can even synchronize audio to video that aligns with the video by adjusting various elements such as sound effects, visuals, and timing to ensure they match perfectly. Without the need for humans to arrange audio to match the video visuals.
Also Read: Google Gemini App finally available on Andriod devices in India
V2A safety concerns
One of the concerns things is AI safety and Google is committed to making this model safe for people and communities. Google takes the concerns from various fields like leading creators and filmmakers, to get feedback during the research and development process.
To address the potential misuse of these models Google incorporated with SynthID toolkit into V2A research watermark all AI-generated content.
Conclusion
Google will use advanced technology to make this process of generating audio and synchronize it with the video to be accurate and match perfectly with the video mood and users’ preferences. However, this model is under research for further development and currently has limits that can be addressed by research and continued development before it is opened to the public.